
Packet Scheduling
여러 개의 Station이 채널을 쓰려할 때 누가 채널을 쓸 지 결정한다.
- 큐에 대기 중인 패킷 중에서 전송할 패킷을 선택한다.
- Station에 대한 대역폭 할당을 제어한다.
- Category
- Intra-station / Inter-station
- Hierarchical / Flat
- Hierarchical: Station에 먼저 할당된 대역폭은 station 내 알고리즘을 기반으로 station 내부에 분대된다.
- Flat: Scheduling은 모든 station의 모든 queue를 기반으로 한다.

FIFO packet scheduling
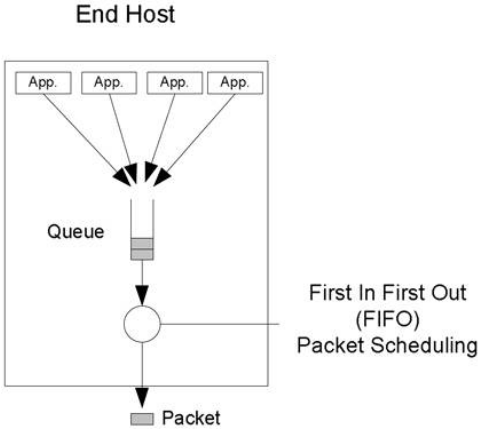
- 간단한 큐잉 메커니즘: 큐에 쌓인 순서대로 패킷을 하나씩 보낸다.
- Best-Effort Service(BOS)에 가장 적합한 스케쥴링 방식이다.
Strict Priority packet scheduling

- 큐에 우선순위를 부여하는 방법이다.
- 숫자가 낮을수록 우선순위가 높다. 큐에 패킷이 있는지 보고 이 중 가장 우선순위가 높은 패킷부터 서비스를 수행한다.
- 패킷마다 Bandwidth와 delay 둘 다에 대해 차별화된 서비스를 제공할 수 있다.
- 우선 순위가 낮은 큐의 패킷은 서비스를 계속 받지 못하는 문제가 발생할 수 있다. -> Starvation 문제
Weighted Fair Queueing

- Starvation 문제를 해결하기 위해 고안되었다.
- 각 큐마다 가중치가 있다. 가중치 <=> BW의 지분
- Weight에 의해 고정된 양의 BW를 할당받는다. -> (가장 최악의 경우) 다른 Station을 고려하지 않고 각 Station의 Delay의 상한을 계산할 수 있다.-> 차별화된 품질 서비스를 제공할 수 있다.
- 결국 큐마다 독점적인 Link(고정된 BW)를 갖는 것처럼 행동한다.
Channel-State-Dependent Scheduling in Wireless Networks
채널 상태에 따른 스케쥴링 방식이다.
유선의 경우는 error-free link를 가정하여 스케쥴링하면 100% 성공해야하지만, 무선의 경우는 네트워크가 매우 유동적이기 때문에 스케쥴링을 하더라도 100%로 채널을 보장하지 못한다.
- 채널 상태 의존 스케쥴링 방식의 시나리오
- 기지국 아래에 여러 개의 mobile station이 존재한다.
- Data packet은 MS에서 BS 방향으로 즉, Up-Link이다.
- 모바일 사용자 별로 패킷의 queue가 존재하고, 기지국의 스케쥴러가 패킷이 전송되는 순서를 정리한다.
- Earlier Methods
- Fixed allocation: 고정된 양만큼 채널을 할당한다. 이전에는 circuit-switched voice channel에서 데이터를 보내는데 사용하기에 알맞았으나, 현재의 데이터 트래픽은 매우 bursty한 구조(듬성듬성한 형태)를 가져서 user가 데이터를 보내지 않는 경우 BW가 낭비된다.
- Dynamic allocation: 동적으로 BW를 할당한다.
- Round-robin: BW를 User들이 돌아가면서 할당받는 방식이다. 이전에 설명했던 Fixed랑 거의 같은 방식이다. (channel-state-independent scheduling)
- 만약 MS가 3개이고, 3개 중 1개를 고를 확률은 동일하다고 가정하자. 만약 Slot 중 임의의 한 Slot을 골랐을 때 그것이 내가 사용할 Slot일 확률은 1/3이며, 이 때 채널의 ON/OFF 확률이 각각 1/2이면, Throughput(slot 당 패킷 전송 성공 확률)은 S = 1/3 * 1/2 = 1/6 이 된다.
- Channel-state-dependent scheduling: 유저에게 우선권을 부여하여 좋은 상태에 채널을 부여하는 방식이다.
- 각 MS 중에서 채널 상태가 ON인 MS만 스케쥴링한다. 단 여러 개가 ON인 경우엔 임의로 하나를 선택한다. 따라서 MS가 3개인 경우 S = 1/3 * (1 - 1/2 * 1/2 * 1/2) = 7/24이다. (뒤 식은 A,B,C가 모두 OFF인 경우를 제외하는 부분). 두 번째의 방식이 첫 번째보다 더 좋은 Throughput을 가진다.
- Round-robin: BW를 User들이 돌아가면서 할당받는 방식이다. 이전에 설명했던 Fixed랑 거의 같은 방식이다. (channel-state-independent scheduling)

Proportional Fairness (PF)
채널의 시변성을 고려하여 좋은 Throughput을 가짐과 동시에 사용자에게 동일한 자원을 제공하는 것을 목표로 한다.
기지국의 스케쥴러가 좋은 채널만 선택하여 다른 MS의 사용이 억압되는 경우가 발생하는 것을 방지한다.
알고리즘은 다음과 같다.

- 해당 분수 식을 가장 크게 만드는 i를 찾아야 한다.
- 식을 크게 만드는 i가 현 시간 t에서 가장 빠른 스피드를 갖는 MS의 id를 의미하며 이를 j에 저장한다.
- Ri(t)가 의미하는 것은 MS i의 채널 상태이고, Ri(t)_hat이 의미하는 것은 MS i의 평균 누적 전송 속도이다.
- 분자를 분모로 나눔으로써 여태까지 채널을 많이 사용한 경우엔(Ri(t)_hat이 증가) 분수 값이 작아지게 되어, 다른 MS로 양보를 하게 된다.

- Ri(t)_hat은 위와 같이 다시 표현할 수 있다. tc는 각 user가 전송까지 최대한 기다릴 수 있는 시간을 의미한다. tc가 크면 클수록 오랫동안 해당 MS가 스케쥴링 되지 않은 것이라고 볼 수 있다. 이 때 1/tc=0에 가까워지며, Ri(t)_hat이 dominant해지며 Ri(t)/Ri(t)_hat의 값이 상대적으로 증가하면서 MS가 스케쥴링될 확률이 커진다.
- 1/tc=1이면 현재 값만 신경쓰고, 1/tc=0이면 과거 값만 신경쓴다.
- 최근 값에 가중치를 더 줌으로써 채널이 좋았다가 나빠지는 등 변화가 심할 때, 최근에 채널이 좋은 MS에 가중치를 더 줘서 그 MS로 스케쥴링한다. -> EWHA(Exponentially Weighted Moving Average, 가중치를 두는 평균 방식)
- PF 스케쥴링 방식을 이용하면 MS 간의 스케쥴링된 시간의 %를 공정하게 가져갈 수 있다. (Throuput을 동일하게 가져가는 것이 아니다)
PF 스케쥴링 방식의 Fairness에 대한 예시가 다음과 같다.

- Ra(t) = alpha, Rb(t) = beta라고 하자. 이 때 PF에 의해, Ra(t)/Ra(t)_hat = Rb(t)/Rb(t)_hat이다.
- ta는 A가 스케쥴링된 시간이라면, 1-ta(=tb)는 B가 스케쥴링된 시간이다. 여기에 MS의 채널 상태를 의미하는 R(t)를 각각 곱하면 위 그림의 식이 된다. 따라서 위 그림의 식이 성립하기 위해선 ta=tb=0.5를 만족해야 한다. -> 이것이 PF 스케쥴링 방식의 시간의 공정성이다.