

Pandas
- Python Data Analysis
- 데이터 분석 및 조작을 위한 파이썬 라이브러리
- 대용량의 데이터들을 처리하는데 매우 편리
- R에서 사용되던 data frame 구조를 본뜬 DataFrame이라는 구조를 사용
- Pandas 자료구조
- Series: 1차원
- DataFrame: 2차원
- Panel: 3차원



Pandas 라이브러리 불러오기
- pandas는 주로 pd라는 약칭으로 사용된다.
import pandas as pd
Pandas Series
Series 생성
series = pd.Series([1.0, 2.0, 3.0, 4.0, 5.0, 6.0])
series0 1.0
1 2.0
2 3.0
3 4.0
4 5.0
5 6.0
dtype: float64- pandas 라이브러리의 Series 메서드로 생성할 수 있다.
- Series 메서드명 앞이 대문자임에 유의하자.
인덱스 및 name 지정
import pandas as pd
series = pd.Series([1.0, 2.0, 3.0, 4.0, 5.0, 6.0], index=['a', 'b', 'c', 'd', 'e', 'f'], name='Example')
seriesa 1.0
b 2.0
c 3.0
d 4.0
e 5.0
f 6.0
Name: Example, dtype: float64- 숫자 인덱스에 문자열 인덱스(별명)를 지정할 수 있다.
- 문자열 인덱스로 지정하더라도 숫자 인덱스를 통한 참조는 여전히 가능하다.
Dictionary → Series
import pandas as pd
# dictionary
data = {
'a' : 1.0,
'b' : 2.0,
'c' : 3.0,
'd' : 4.0,
'e' : 5.0,
'f' : 6.0
}
series = pd.Series(data)
seriesa 1.0
b 2.0
c 3.0
d 4.0
e 5.0
f 6.0
dtype: float64- 딕셔너리 자료형을 이용하여 Series를 생성할 수 있다.
Pandas DataFrame
- DataFrame은 여러 개의 시리즈가 모여 하나의 행렬로 구성된 데이터이다.
- DataFrame은 딕셔너리 등의 자료형이나, 외부의 CSV 파일, Excel 파일을 불러와서 만들 수 있다.
DataFrame 생성
import pandas as pd
df = pd.DataFrame()- dataframe은 pandas 라이브러리의 DataFrame() 메서드를 사용하여 생성한다.
여러 개의 Series로 DataFrame 생성
import pandas as pd
height_dict = {
'Suzy' : 162.8,
'Minsung' : 180.1,
'Kevin' : 175.0
}
weight_dict = {
'Suzy' : 48.3,
'Minsung' : 75.8,
'Kevin' : 82.1
}
height = pd.Series(height_dict)
weight = pd.Series(weight_dict)
df = pd.DataFrame({
'height' : height,
'weight' : weight
})
print(type(height),'\n',type(weight),'\n',type(df)) # 타입 확인
df # dataframe 출력<class 'pandas.core.series.Series'>
<class 'pandas.core.series.Series'>
<class 'pandas.core.frame.DataFrame'>
- 2개의 Series를 연결하여 1개의 Dataframe을 생성하였다.
Dictionary → DataFrame 변환
- DataFrame()에 사전 자료형을 매개변수로 넣어 DataFrame으로 변환할 수 있다.
import pandas as pd
# dictionary
data = {
'name': ['Suzy', 'Minsung', 'Kevin', 'Minhyuk', 'Wang', 'Hyunsoo'],
'year':[1998, 2001, 1993, 1999, 1989, 2005],
'height': [162.8, 180.1, 175.0, 172.1, 192.3, 165.2],
'weight': [48.3, 75.8, 82.1, 70.3, 89.3, 63.2]
}
df = pd.DataFrame(data)
df
CSV → DataFrame 변환
- CSV(Comma-Separated Values): 몇 가지 필드를 쉼표(,)로 구분한 텍스트 데이터 및 텍스트 파일
- read_csv() 함수를 이용한다. (excel 파일은 read_excel() 함수를 이용한다.)
- dataframe을 csv 파일로 저장할 때는 to_csv() 함수를 이용한다. (excel 파일은 to_excel() 함수를 이용)

위 csv 파일을 불러와서 DataFrame으로 변환한다.
csv_data = pd.read_csv('C:/jupyter/pandas_data.csv') # dir_name
csv_data
Dictionary를 이용하여 만든 DataFrame과 동일한 DataFrame을 생성하였다.
기초 method
- Pandas에서 사용 가능한 기초 method에 대해 알아보자.
- 모든 method는 앞서 만들었던 위의 Dataframe을 기준으로 수행한다.
Index 설정하기
- set_index를 이용하여 원하는 열(column)을 index로 지정할 수 있다.
df = df.set_index('name')
df
df.head()
- DataFrame의 상위 5개 행의 데이터만 보여줌 (default)
- 괄호 안에 숫자를 넣어 개수를 지정할 수 있음.
df.head()
df.index
- DataFrame의 index를 반환한다.
- 문자열이 index나 column 명에 들어가는 경우 모든 요소는 object 데이터 타입으로 지정된다.
df.indexIndex(['Suzy', 'Minsung', 'Kevin', 'Minhyuk', 'Wang', 'Hyunsoo'], dtype='object', name='name')
df.columns
- DataFrame의 column을 구한다.
df.columnsIndex(['year', 'height', 'weight'], dtype='object')
df.info()
- DataFrame의 요약을 보여준다.
df.info()<class 'pandas.core.frame.DataFrame'>
Index: 6 entries, Suzy to Hyunsoo
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 year 6 non-null int64
1 height 6 non-null float64
2 weight 6 non-null float64
dtypes: float64(2), int64(1)
memory usage: 192.0+ bytes
df.describe()
- Column 단위로 DataFrame의 통계를 제공한다.
df.describe()
Data 추출
인덱싱(Indexing)을 이용한 추출

- column 'year'을 indexing하여 row 별 데이터 추출
df['year']name
Suzy 1998
Minsung 2001
Kevin 1993
Minhyuk 1999
Wang 1989
Hyunsoo 2005
Name: year, dtype: int64
슬라이싱(Slicing)을 이용한 추출(1)
- index value를 기준으로 slicing
- 문자 인덱스를 이용한 슬라이싱은 마지막 인덱스(예제에서는 'Minhyuk')도 포함한다.
df['Suzy':'Minhyuk']
슬라이싱을 이용한 추출(2)
- 숫자 인덱스를 이용하여 추출
- 숫자 인덱스 슬라이싱을 이용할 때는 기존 방식과 동일하게 마지막 인덱스(예제에서는 3)을 제외한다.
df[:3]
column 리스트를 이용한 추출
- 특정 column의 데이터만 추출
df[['height', 'weight']]
loc, iloc 이용한 추출
loc 이용하기
- loc에 index value(문자 인덱스)를 대입하여 데이터 추출
df.loc['Minsung']year 2001.0
height 180.1
weight 75.8
Name: Minsung, dtype: float64
loc와 슬라이싱 함께 쓰기
df.loc['Minsung':'Wang', :'height'] # 'wang'과 'height'까지도 포함
- loc와 슬라이싱을 함께 사용하여 특정값을 추출할 수 있다.
- 'Minsung'부터 'Wang'까지의 값 중에서 'height' 열까지의 데이터만 추출한다는 의미
- 숫자 인덱스를 사용한 슬라이싱과 다른 점은 마지막 인덱스까지 포함한다는 것이다. (숫자 인덱스를 통한 슬라이싱은 마지막 인덱스-1 임)
iloc 이용하기

- iloc에 특정 위치의 값(숫자 인덱스)을 대입하여 데이터 추출
df.iloc[2]year 1993.0
height 175.0
weight 82.1
Name: Kevin, dtype: float64
iloc와 슬라이싱 함께 쓰기
df.iloc[0:4, 0:2] # 0~3 인덱스까지의 데이터 중 0~1 열까지의 데이터
- iloc와 숫자 인덱스를 통해서도 데이터 추출이 가능하다.
- loc와 슬라이싱을 사용한 추출 방법과 다르게, iloc와 슬라이싱을 이용한 추출은 기존 방식과 동일하게 마지막 인덱스 -1 까지의 데이터만 추출한다.
추출한 index로 loc 이용하기
- index 추출 후, loc에 대입하여 데이터 추출
df.loc[df.index[0]] # df.index[0] == 'Suzy'year 1998.0
height 162.8
weight 48.3
Name: Suzy, dtype: float64
column 리스트를 loc에 이용하기
- loc와 column 리스트를 이용하여 특정 column 데이터만 추출하기
df.loc[:, ['height', 'weight']]
Data 추가
행(row) 추가

> 위 DataFrame을 기준으로 행(row) 추가를 수행
pd.concat([dataframe, new_dataframe])
new_dict = {'name': ['Suho'],
'year': [2002],
'height': [187.2],
'weight': [72.5],
}
new_df = pd.DataFrame(new_dict)
df = pd.concat([df, new_df])
df
append 함수 이용
1) dictionary로 추가하기
- df.append(new_dict, ignore_index=True)
new_dict = {'name': 'Suho',
'year': 2002,
'height': 187.2,
'weight': 72.5,
}
df = df.append(new_dict, ignore_index=True)
df
2) dataframe으로 추가하기
- df.append(new_df, ignore_index=True)
df2 = pd.DataFrame({'name': ['Suho', 'Minzy'],\
'year': [2002, 2003],\
'height': [187.2, 165.3],\
'weight': [72.5, 52.5]})
df = df.append(df2, ignore_index=True)
df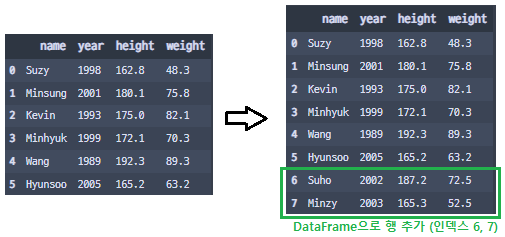
df.loc[마지막 인덱스 + 1] = value list
df.loc[df.index[-1] + 1] = ['Suho', 2002, 187.2, 72.5]
df
> 만약 마지막 인덱스 + 1을 넣지 않고, 중간 인덱스 번호를 넣는 경우, Data가 추가되는 것이 아니라 교체된다.
중간에 추가하기 (실제로는 기존 dataframe을 분할하고, 중간에 새로운 data를 넣는 형식)
- concat, iloc를 함께 사용한다.
- pd.concat([df.iloc[:index], new_data, df.iloc[index:]], ignore_index=True)
df2 = pd.DataFrame({'name': ['Suho', 'Minzy'],\
'year': [2002, 2003],\
'height': [187.2, 165.3],\
'weight': [72.5, 52.5]})
df = pd.concat([df.iloc[:2], df2, df.iloc[2:]], ignore_index = True)
df
열(column) 추가
마지막에 열 추가하기
- column명이 없는 경우에는 추가하고자 하는 column 명을 입력하고, value를 같이 지정하면 된다.
- 아직 value가 따로 없을 시, value 대신에 np.nan을 이용하여 NaN 값을 넣도록 하자.
df['country'] = ['korea', 'korea', 'usa', 'korea', 'china', 'korea']
# df['country'] = np.nan 값이 없을 시
중간에 열 추가하기
- df.insert(위치, column 명, value list)로 추가 가능
df.insert(1, 'age', [24, 21, 29, 23, 33, 17])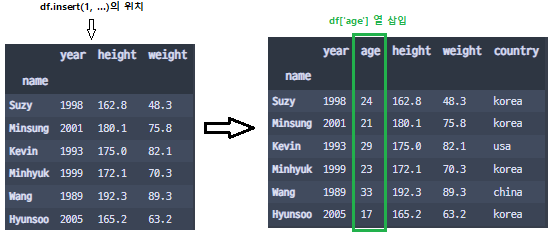
Data 삭제

> 위 DataFrame을 이용하여 수행
행(row) 삭제
drop() 함수 이용
- df.drop(index, axis=0) # axis는 생략 가능. default가 axis=0.
- df.drop([i, j, k ...]) # 여러 행 동시에 삭제 가능
- drop 함수는 inplace=False가 defualt이므로, inplace=True로 지정하면 dataframe을 새로 만들 필요없이 drop 함수만으로도 기존의 dataframe을 변경시킬 수 있다.
df = df.drop(3, axis=0)
df
df = df.drop([1, 3, 5])
df
슬라이싱 이용
- slicing으로 삭제
- df[1:4]이면 1행부터 3행까지만 추출
df = df[1:4]
df
query 함수 이용
- df.query('column명 != value')
df = df.query('name != "Minsung"')
df
열(column) 삭제
drop 함수 이용
- df.drop(column 명, axis=1)
- df.drop(column 명, axis='columns')
- df.drop([column1, columns2, ...], axis=1)
df = df.drop('year', axis=1)
df
df = df.drop('height', axis='columns')
df
df = df.drop(['year', 'height'], axis=1)
df
Data 수정
> 위 Dataframe을 기준으로 수행
loc 이용하여 수정
특정 행 모든 value 바꾸기
df.loc[0] = ['Hojin', 1995, 175.3, 72.1]
df
- loc를 이용하여 0번 행('Suzy' 인덱스)에 접근하여 값을 변경하였다.
특정 행 일부 value 바꾸기
df.loc[0, 'weight'] = 47.5
df.loc[1, ['year', 'height']] = [2000, 180.5]
df
- loc를 이용하여 특정 행의 인덱스와, 바꾸고자 하는 열 이름을 적으면 된다.
replace 함수를 이용
df = df.replace(2001, 1999) # replace(이전값, 변경값)
df = df.replace(2005, 1999) # df.replace(2005, 1999, inplace=True)
df
- replace를 이용하면 Dataframe의 모든 데이터에 대해 변경이 진행된다.
- replace 메서드의 inplace 매개변수를 True로 두면 Dataframe 대입 과정을 생략할 수 있다.
- 위 코드 동작으로 인해, Minsung과 Hyunsoo의 year 데이터 값이 변경되었다.
apply 함수 이용
def del_point(x): # 소수점 제거
return int(x)
df['height'] = df['height'].apply(del_point) # 기존 함수 이용
df['weight'] = df['weight'].apply(lambda x: int(x)) # lambda 식 이용
df
- apply 함수를 이용하여 특정 열에 값을 변경하는 함수를 적용할 수 있다.
- 함수를 apply에 매개변수로 넘기는 경우에는 () 소괄호를 적지 않아야 함에 유의하자.
Masking 연산
- numpy에서 사용하는 masking 연산을 pandas에서도 동일하게 사용할 수 있다.
- 마스킹 연산이 무엇인지 모르겠다면 numpy 게시글 참고
Numpy 라이브러리
Numpy Numerical Python 수학 및 과학 연산을 위한 파이썬 패키지 Numpy 내부는 상당부분이 C나 Fortran으로 작성되어 있어 실행 속도가 꽤 빠른 편이다. 기본적으로 array라는 자료를 생성하고, 이를 바탕으
wn42.tistory.com
Masking 사용하여 데이터 추출하기
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(3, 3), columns=['A', 'B', 'C'])
df
- Masking을 위해 새로운 Dataframe을 생성하였다.
Mask 생성하기
df["A"] > 0.3, df["B"] < 0.5, df["C"] < 0.2(0 False
1 True
2 True
Name: A, dtype: bool,
0 True
1 True
2 True
Name: B, dtype: bool,
0 False
1 True
2 True
Name: C, dtype: bool)- 비교 연산자를 이용하여 bool 형식의 Mask를 생성할 수 있다.
- bool 형식의 mask를 이용할 때 데이터는 True 일 때만 출력된다.
- 위 Mask를 이용하여 모든 조건에 대해 True인 데이터만 추출하도록 해보자.
Mask 이용하여 데이터 추출
df[(df["A"] > 0.3) & (df["B"] < 0.5) & (df["C"] < 0.2)] # &는 and를 의미
- 모든 조건에 대하여 True인 행은 1번, 2번 인덱스 행이므로 Masking에 의해 해당 행들만 추출되었다.
query 함수 이용하기
df.query("A > 0.3 and B < 0.5 and C < 0.2")
- query 함수에 조건식을 작성하여 데이터를 추출할 수 있다.
- 보통 query보다는 더욱 직관적으로 조건을 이해할 수 있는 masking 방식을 이용하는 편이다.
누락 데이터 수정
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(3, 3), columns=['A', 'B', 'C'])
for i, col in enumerate(['A', 'B', 'C']):
df.loc[i, col] = np.nan
df
- NaN 값이 존재하는 Dataframe을 생성하였다.
isnull() / notnull()
isnull()
df.isnull()
- isnull() 함수는 누락 데이터에 대해 True를 반환하며, bool 형식의 mask를 얻을 수 있다.
notnull()
df.notnull()
- notnull() 함수는 누락되지 않은 데이터에 대해서 True를 반환한다.
Masking으로 누락 데이터 수정하기
df[df.isnull()] = 0
df
- Dataframe에 masking을 적용하면, True인 값(누락값)에 대해서 0을 대입하는 코드가 수행된다.
fillna()
df = df.fillna(0) # df.fillna(0, inplace=True)
df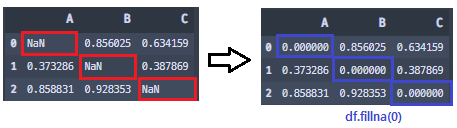
- fillna()라고 누락 값에 특정 값을 채워주는 함수가 존재한다. 이것을 사용하는 편이 더 간단하다.
dropna()
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.rand(3, 3), columns=['A', 'B', 'C'])
df.loc[0] = np.nan
df
- dropna()는 누락값이 포함된 행/열을 제거하는 함수이다. (axis=0는 행, axis=1는 열, default는 행 기준)
- (정확히는 누락값이 제외된 행/열을 반환하는 함수로, 대입 과정 혹은 inplace=True가 필요)
df = df.dropna() # df.dropna(inplace=True)
df
Dataframe 정렬
import pandas as pd
data = [[40, 50, 30], [10, 80, 60], [70, 20, 90]]
df = pd.DataFrame(data, columns=['A', 'B', 'C'])
df
- Dataframe 정렬을 수행하기 위해 3x3 데이터프레임을 생성하였다.
sort_values()
- sort_values()는 데이터프레임을 값(Value)을 기준으로 정렬하는 메서드이다.
- Default 기본 정렬 기준은 행(row)과 오름차순(ascending)이다. (ascending 파라미터의 디폴트값은 True)
- 행이 바뀌는 정렬 ▶ 행 기준 정렬 (axis=0)
- 열이 바뀌는 정렬 ▶ 열 기준 정렬 (axis=1)
df.sort_values('정렬 기준')
df.sort_values('정렬 기준', inplace=True) # inplace 파라미터를 True하면 원 DF의 값이 변함
df.sort_values('정렬 기준', ascending=False) # ascending 파라미터를 False하면 내림차순 정렬
행(row) 기준 정렬
# Column 'A'의 행 기준 (오름차순)
df.sort_values('A')
- 열 'A'에 해당하는 행의 값을 기준으로 정렬을 진행하였다.
- Default 설정에 따라 오름차순으로 정렬이 진행되었음을 알 수 있다.
- 나머지 열 'B'와 'C'의 행은 열 'A'의 정렬 기준에 따라 배치된다.
# Column 'A'의 행 기준 (내림차순)
df.sort_values('A', ascending=False)
- ascending=False로 지정하면 내림차순의 정렬을 수행할 수 있다.
# 여러 Column의 행을 기준으로 정렬
df.sort_values(['C', 'A'])
- sort_values() 메서드에 Column 리스트를 인자로 넘기면, 여러 Column의 행을 기준으로 정렬을 수행할 수 있다.
- Column 리스트의 정렬 순서는 뒤에서부터 앞이다. (위 코드에서는 'A' → 'C' 순서)
열(column) 기준 정렬
df.sort_values(1, axis=1, ascending=False)
- 1번 인덱스 행의 값을 내림차순으로 정렬하였다.
- 1은 1번 인덱스를, axis=1은 열기준 정렬, ascending=False는 내림차순 정렬을 의미한다.
sort_index()
- sort_index()는 데이터프레임을 인덱스(index) 번호를 기준으로 정렬하는 메서드이다. (데이터 값이 아님)
- Default 기본 정렬 기준은 오름차순(ascending)이다. (ascending 파라미터의 디폴트값은 True)
df.sort_index() # 오름차순 정렬
df.sort_index(ascending=False) # 내림차순 정렬
인덱스 정렬
df.sort_index(ascending=False)
- sort_index() 메서드를 이용하여, 인덱스를 내림차순으로 정렬하였다.
그룹화 하기
- Dataframe을 특정 기준으로 집계하기 위해 그룹화를 진행할 수 있다.
import pandas as pd
# dictionary
data = {
'name': ['Suzy', 'Minsung', 'Kevin', 'Minhyuk', 'Wang', 'Hyunsoo'],
'year':[1998, 2001, 1993, 1999, 1989, 2005],
'height': [162.8, 180.1, 175.0, 172.1, 192.3, 165.2],
'weight': [48.3, 75.8, 82.1, 70.3, 89.3, 63.2],
'country': ['Korea', 'Korea', 'USA', 'USA', 'China', 'Korea']
}
df = pd.DataFrame(data)
df
- 실습을 위해 이전에 쓰던 데이터에 'country' 열을 추가하였다.
groupby()
- groupby()는 특정 Column을 index로 사용하여 Dataframe을 집계하고 싶을 때 사용하는 메서드이다.
- groupby()의 반환값은 온전한 Dataframe이 아니며, 반드시 집계함수가 동반되어야 한다.
- groupby()로 Dataframe을 집계할 때 1개 이상의 Column을 index로 사용할 수 있다.
groupby()의 반환값
df.groupby('country')<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000002258119A250>- 집계함수를 사용하지 않은 groupby()의 반환값은 위와 같으며, 반드시 sum(), mean() 등의 함수를 이용하여 데이터를 정리하여야만 온전한 Dataframe이 반환된다.
groupby()와 집계함수를 함께 사용
df.groupby('country').mean() # country마다 평균낸 데이터를 집계하도록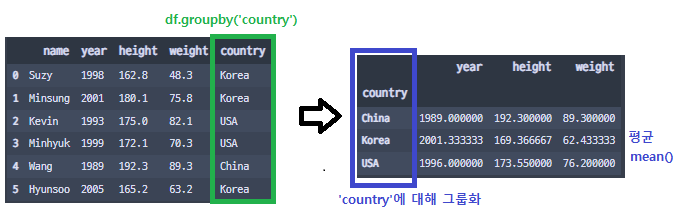
- 'country' 열을 index로 하여 데이터들의 평균(mean)을 집계하도록 코드를 작성하였다.
- 이처럼 groupby()에 index로 설정할 열(column)을 인자로 넘기고 나서, 꼭 집계할 기준함수를 명시해야 한다.
apply() 메서드 사용

- apply() 메서드에 함수를 파라미터로 넘겨서 데이터를 집계할 수 있다.
- 하지만 함수 구현이 기존 집계함수를 사용하는 것보다 까다롭기 때문에 기존 집계함수를 사용하는 것을 추천.
- 함수 구현 시 고려해야 할 사항이 많음
aggregate()
df.groupby('country').aggregate([min, 'mean', max])
- aggregate() 메서드는 여러 개의 집계를 한 번에 계산할 수 있도록 한다.
- aggregate() 파라미터의 따옴표 기준
- 만약 파이썬 기본 집계함수라면 위 코드의 min과 max 처럼 따옴표를 사용하지 않아도 됨.
- 파이썬 기본 집계함수가 아니라면, aggregate에서 지원되는 함수 내에서 따옴표를 통해 사용할 수 있음.
Dictionary 넘기기
df.groupby('country').aggregate({'year':'mean', 'height':max, 'weight':min})
- Dictionary 자료형을 파라미터로 넘기면, 각 Column마다 집계함수를 직접 지정할 수 있다.
filter()
- groupby를 통해 집계한 데이터로부터 Mask를 생성하여 데이터 필터링을 진행할 수 있다.
Filter 함수 생성
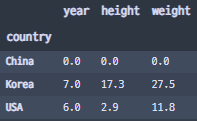
def Filter(x):
return x['height'].mean() > 170- 'height' 열에 대한 평균이 170이 넘는 경우에만 True를 반환하도록 하는 함수를 생성하였다.
- 이 함수는 filter() 메서드의 파라미터로 넘겨질 예정이다.
mean() 데이터 확인
df.groupby('country').mean()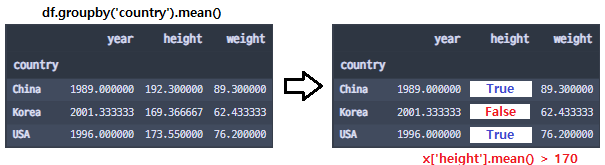
- 'country'를 기준으로 groupby하고, mean() 함수를 통해 평균을 낸 데이터이다.
- 데이터를 보면 China와 USA의 'height' 평균만 170이 넘어감을 알 수 있다.
- 데이터 필터링을 진행하면 China와 USA의 행들만 필터링되어 출력될 것이라고 예상할 수 있다.
데이터 필터링
df.groupby('country').filter(Filter)
- 예상대로 국적이 USA, China인 데이터들만 출력되어 나왔다.
get_group()
df.groupby('country').get_group('Korea')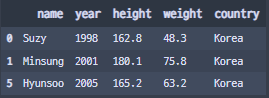
- get_group() 메서드를 통해 groupby를 진행한 데이터에서 특정 key값의 데이터를 추출할 수 있다.
Multi Index
- Dataframe에 다중 index를 설정하여, 여러 계층을 갖는 고차원 데이터를 생성할 수 있다.
Multi index 생성 (메서드 X)
메서드 없이 만들기 (행)
import pandas as pd
data = [[40, 50, 30],
[10, 80, 60],
[70, 20, 90],
[80, 70, 30],
[10, 30, 50],
[80, 50, 40]
]
df = pd.DataFrame(data,
index=[['A', 'A', 'B', 'B', 'C', 'C'], [1, 2, 1, 2, 1, 2]],
columns=['Data1', 'Data2', 'Data3']
)
df
- 행 인덱스를 다중으로 설정하여 계층 구조를 형성하였다.
메서드 없이 만들기 (열)
import pandas as pd
data = [[40, 50, 30, 10, 80, 60],
[70, 20, 90, 80, 70, 30],
[10, 30, 50, 80, 50, 40]
]
df = pd.DataFrame(data,
index=[['A', 'B', 'C']],
columns=[['Data1', 'Data1', 'Data2', 'Data2', 'Data3', 'Data3'],\
[1, 2, 1, 2, 1, 2]]
)
df
- 열 인덱스도 다중 설정이 가능하다.
Multi index 생성 (메서드 O)
pd.MultiIndex.from_arrays(arrays, sortorder=None, names=_NoDefault.no_default)
pd.MultiIndex.from_product(iterables, sortorder=None, names=_NoDefault.no_default)
pd.MultiIndex.from_tuples(tuples, sortorder=None, names=None)
pd.MultiIndex.from_frame(df, sortorder=None, names=None)
pd.Index(data=None, dtype=None, copy=False, name=None, tupleize_cols=True)
pandas.MultiIndex — pandas 2.0.0 documentation
get_indexer(target[, method, limit, tolerance]) Compute indexer and mask for new index given the current index.
pandas.pydata.org
- pandas의 MultiIndex() 라는 메서드를 이용하여 멀티인덱스를 만들 수 있다.
- 인자로 넘기는 자료형에 따라 멀티인덱스로 변환할 수 있다.
- 함수의 파라미터에 대한 내용은 위 사이트를 참고하자.
메서드 사용하여 멀티인덱스 만들기 (행)
import pandas as pd
data = [[40, 50, 30],
[10, 80, 60],
[70, 20, 90],
[80, 70, 30],
[10, 30, 50],
[80, 50, 40]
]
index_arrays = [['A', 'A', 'B', 'B', 'C', 'C'],
[1, 2, 1, 2, 1, 2]
]
index = pd.MultiIndex.from_arrays(index_arrays) # 인덱스 설정
df = pd.DataFrame(data, columns=['Data1', 'Data2', 'Data3'], index = index)
df
메서드 사용하여 멀티인덱스 만들기 (열)
import pandas as pd
data = [[40, 50, 30, 10, 80, 60],
[70, 20, 90, 80, 70, 30],
[10, 30, 50, 80, 50, 40]
]
column_arrays = [['Data1', 'Data1', 'Data2', 'Data2', 'Data3', 'Data3'],\
[1, 2, 1, 2, 1, 2]
]
columns = pd.MultiIndex.from_arrays(column_arrays) # 인덱스 설정
df = pd.DataFrame(data, columns=column_arrays, index = ['A', 'B', 'C'])
df
Multi Index 데이터 조회
- 기존 인덱싱 방식 혹은 loc, iloc를 이용하여 조회가 가능하다.
기존 indexing 방식
print(df['Data1'])
print('---------------')
print(df['Data2'][1])A 1 40
2 10
B 1 70
2 80
C 1 10
2 80
Name: Data1, dtype: int64
---------------
80
loc, iloc 이용
print(df.loc['A'])
print('---------------')
print(df.iloc[2][1]) # ['B']['Data2'] Data1 Data2 Data3
1 40 50 30
2 10 80 60
---------------
20
Pivot Table
pandas.pivot_table — pandas 2.0.0 documentation
If list of functions passed, the resulting pivot table will have hierarchical columns whose top level are the function names (inferred from the function objects themselves) If dict is passed, the key is column to aggregate and value is function or list of
pandas.pydata.org
- Pandas에서는 엑셀에서 주로 사용되는 Pivot Table 기능을 구현할 수 있는 함수인 pivot_table()을 제공한다.

Pivot Table 문법
pandas.pivot_table(data, values=None, index=None, columns=None, aggfunc='mean',
fill_value=None, margins=False, dropna=True, margins_name='All',
observed=False, sort=True)- data: Dataframe
- values: 분석에 사용할 열
- index: 피벗테이블의 행 인덱스로 들어갈 'Key' (그룹화할 칼럼명)
- columns: 피벗테이블의 열 인덱스로 사용될 'Key' (분석되는 values 데이터를 좀 더 세분화하는 역할)
- aggfunc: 피벗테이블을 형성할 때 데이터에 적용되는 집계함수
- fill_value: 누락값이 존재할 시 이를 대체할 값
- margins:오른쪽 끝과 아래 끝에 데이터의 총합산을 나타내고 싶을 때 사용
- dropna: 모든 항목이 Nan인 열을 제외할 때 사용 (default=True)
- margins_name: margins의 이름을 정하는 파라미터 (default 명 = All)
- observed: 범주형으로 그룹화된 데이터에서 적용하는 파라미터
- sort: 데이터를 정렬할지 말지 결정하는 파라미터
Pivot Table 만들기
사용할 데이터 프레임
import pandas as pd
# dictionary
data = {
'name': ['Suzy', 'Minsung', 'Kevin', 'MinJi', 'Wang', 'Hyunsoo'],
'sex' : ['Female', 'Male', 'Male', 'Female', 'Male', 'Male'],
'year':[1998, 2001, 1993, 1999, 1989, 2005],
'height': [162.8, 180.1, 175.0, 172.1, 192.3, 165.2],
'weight': [48.3, 75.8, 82.1, 68.3, 89.3, 63.2],
'country': ['Korea', 'Korea', 'USA', 'USA', 'China', 'Korea']
}
df = pd.DataFrame(data)
df
성별 및 국적에 따른 키/몸무게 평균 정리
df.pivot_table(
values = ['height', 'weight'],
index = 'sex',
columns = 'country',
aggfunc = np.mean,
fill_value = 'X'
)
- 성별과 국적에 따라 키/몸무게 평균을 정리하였다.
- China 국적의 여성 값이 없기에 해당 평균은 Nan값이며, fill_value로 인해 Nan값이 'X'로 치환되었다.