STL은 다양한 자료형으로 사용할 수 있도록 만든 함수 템플릿이나 클래스 템플릿이 기초가 된다.
여기서는 STL에 있는 자료구조 클래스를 이용한다.
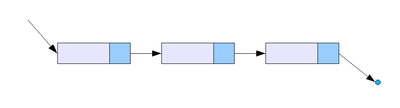
연결리스트(Linked List)
어떤 데이터 덩어리(이하 노드 Node)를 저장할 때 그 다음 순서의 자료가 있는 위치를 데이터에 포함시키는 방식으로 자료를 저장
#include <list>
시간복잡도
삽입/삭제: O(1)
탐색: O(n)
데이터의 추가/삭제가 많은 경우에는 연결 리스트를 사용하면 좋다.
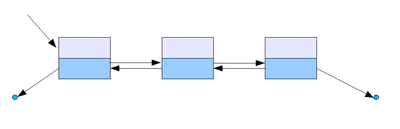
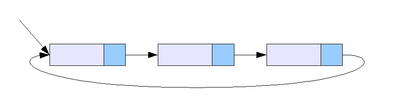
단순 연결 리스트이중 연결 리스트원형 연결 리스트
싱글 연결 리스트: next 포인터만 가짐
이중 연결 리스트: next 포인터와 prev 포인터를 가짐
원형 이중 연결 리스트: 이중 연결리스트와 동일한 형태이지만 마지막 노드의 next 포인터가 헤드 노드(맨 앞 노드)를 가리킴
#include <iostream>
#include <list>
using namespace std;
int main(){
// 리스트 선언
list<int> temp;
// push_back -> 뒤에서 값 넣기
for (int i=0; i<10; i++){
temp.push_back(i);
}
// push_front -> 앞에서 값 넣기
for (int i=0; i<10; i++){
temp.push_front(i);
}
// insert(인덱스, 값)
auto index = ++temp.begin();
temp.insert(index, -1);
for (int a: temp){
cout << a << " ";
}
cout << endl;
// 맨 앞 원소 제거하기
temp.pop_front();
// 맨 뒤 원소 제거하기
temp.pop_back();
for (int a: temp){
cout << a << " ";
}
return 0;
}
#include <iostream>
#include <vector>
#include <queue>
using namespace std;
void print_queue(auto pq){
while(pq.size()){
cout << pq.top() << " ";
// 큐 가장 앞부분 제거
pq.pop();
}
cout << endl;
}
int main(){
priority_queue<int> pq1; // default는 최대 우선순위 큐
int random_num[6] = {10, 30, 40, 60, 50, 20}; // 크기 상관없이 랜덤
// 1. 요소 삽입
for (int i=0; i<6; i++){
pq1.push(random_num[i]);
}
print_queue(pq1); // 삽입한 순서에 상관없이 가장 큰 요소가 먼저 출력
// 2. 최소 우선순위 큐
// priority_queue<자료형, 구현체, 비교연산자>에서 greater를 이용하여 작은 int값을 우선으로 설정
priority_queue<int, vector<int>, greater<int>> pq2; // greater 대신 less를 쓰면 최대 우선순위 큐
for (int i=0; i<6; i++){
pq2.push(random_num[i]);
}
print_queue(pq2); // 삽입 순서에 상관없이 작은 값부터 출력
return 0;
}
60 50 40 30 20 10
10 20 30 40 50 60
맵(Map)
특정 순서에 따라 키와 매핑된 값의 조합으로 형성된 자료구조로 map의 key는 유일하다. (중복 허용 X)
같은 key값을 갖는 원소를 저장하고 싶다면 multimap을 사용한다.
레드 블랙 트리 자료 구조 기반으로, 요소 삽입시 자동 정렬됨
map은 해시테이블을 구현할 때 사용하며 정렬을 보장하지 않는 unordered_map과 정렬을 보장하는 map이 있음
key를 이용하여 value를 빠르게 검색할 수 있는 연관 컨테이너이다.
기본 형태: map<key, value>
#include <map>
시간 복잡도
탐색/삽입/삭제: O(logn)
#include <iostream>
#include <map>
#include <string>
using namespace std;
int main(){
// 1. map 선언
map<string, int> m;
string keys[3] = {"David", "Paul", "Kevin"};
// 2. map에 요소 삽입
m.insert({keys[0], 26}); // 1) {key, value} 이용
m.insert(make_pair(keys[1], 25)); // 2) pair 객체 이용
m[keys[2]] = 27; // 3) [key] = value 이용
for (int i=0; i<m.size(); i++){
cout << keys[i] << ":" << m[keys[i]] << " ";
}
cout << endl;
// 3. 요소 수정하기
m[keys[2]] = 29; // Kevin의 value를 27 -> 29로 변경
for (int i=0; i<m.size(); i++){
cout << keys[i] << ":" << m[keys[i]] << " ";
}
cout << endl;
// 3. map에서 요소 확인하기.
if (m.find("Smith") != m.end()){
cout << "Find" << endl;
}else{
cout << "Not Find" << endl;
}
// 4. iterator 사용하여 요소 출력
map<string, int>::iterator iter;
for(iter=m.begin(); iter!=m.end(); iter++){
cout << iter->first << ":" << iter->second << " ";
}
cout << endl;
iter = m.find("Kevin"); // key가 Kevin인 요소 찾기
cout << iter->first << ':' << iter->second << " " << endl;
// 5. 반복문 사용하여 요소 출력
for (auto i: m){
cout << i.first << ":" << i.second << " ";
}
cout << endl;
// 6. map에서 요소 삭제하기
// 1) 인덱스 요소 삭제
m.erase(++m.begin());
for (auto i: m){
cout << i.first << ":" << i.second << " ";
}
cout << endl;
// 2) 키 값 기준으로 삭제
m.erase("Paul");
for (auto i: m){
cout << i.first << ":" << i.second << " ";
}
cout << endl;
// 3) erase를 사용하여 모든 요소 제거
// map 초기화
m["a"] = 1;
m["b"] = 2;
for (auto i: m){
cout << i.first << ":" << i.second << " ";
}
cout << endl;
// erase
m.erase(m.begin(), m.end());
for (auto i: m){
cout << i.first << ":" << i.second << " ";
}
cout << endl;
// 4) clear 함수로 모든 요소 제거
// map 초기화
m["a"] = 1;
m["b"] = 2;
for (auto i: m){
cout << i.first << ":" << i.second << " ";
}
cout << endl;
// clear
m.clear();
for (auto i: m){
cout << i.first << ":" << i.second << " ";
}
cout << endl;
return 0;
}
![[C++] STL 자료구조](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FDmG20%2FbtrSKQDy2A8%2FK3BOC7TEUklp9Q7P7W8aP0%2Fimg.png)