임베디드 환경에서는 MobileNet처럼 경량화된 모델을 사용하여 딥러닝 연산을 수행하면 좋다.
MobileNet에 대해서는 나중에 논문 리뷰를 할 예정이다. (도대체 언제 할거니)
이번에는 MobileNet에 대해서 설명하기 보다 구글에서 제공하는 모델 학습 파일을 리뷰한다.
Retrain MobileNet V2 classifier for the Edge TPU (TF2)
Run, share, and edit Python notebooks
colab.research.google.com
Retrain a classification model for Edge TPU using post-training quantization (with TF2)
대충 번역하면 훈련 후 양자화를 이용한 분류 모델 재훈련이다.
임베디드 환경에서는 기존의 딥러닝 모델을 사용하기에는 메모리나 성능에서 한계가 있기 때문에 이를 해결하기 위해 TensortFlow Lite는 데이터 타입을 32bit 부동 소수점 숫자에서 8bit 고정 소수점 숫자로 경량화하는 정수양자화를 진행한다.
훈련 후 양자화란 모델 정확성을 거의 저하시키지 않으면서 CPU 및 하드웨어 가속기 지연 시간을 개선하고 모델 크기를 줄일 수 있는 변환 기술이다. TF Lite 변환기를 사용하여 이미 훈련된 부동 TF 모델을 TF Lite 형식으로 변환하면서 양자화를 진행한다.
이 튜토리얼에서는 TF2를 이용하여 이미지 분류 모델을 만든 후, 훈련 후 양자화를 사용하여 TF Lite 모델로 변환한다.
그리고 이 튜토리얼에서는 이미 어느정도 학습된 MobileNet V2를 기반으로 진행된다.
여기서는 분류 레이어만 재트레이닝하고 MobileNet의 사전 트레이닝된 기능 추출 레이어는 다시 사용한다.
그다음 일부 기능 추출 레이어의 일부의 웨이트만 조금씩 조정해나갈 것이다.
이러한 전이학습은 전체를 처음부터 학습하는 것보다 빠르게 학습을 마칠 수 있다.
트레이닝이 완료되면 모든 파라미터는 int8 타입으로 변환된다. 모델 사이즈가 작아지고, 추론시간이 빨라진다. 그리고 이러한 타입이 Edge TPU에서 구동하는 데 호환성이 좋다.
참고: 완전 양자화를 진행하려면 TF 2.3+ 버전이 필요한데 현재 일부 모델에 적용이 안된다고 한다. 특히 이번 튜토리얼은 keras 모델을 사용하며, frozen graph 구조에는 적용되지 않는다고 한다.
Import the required libraries
텐서 데이터를 양자화하기 위해서 TFLiteConverter API를 불러올 필요가 있다.
import tensorflow as tf
assert float(tf.__version__[:3]) >= 2.3
import os
import numpy as np
import matplotlib.pyplot as pltTF의 버전은 2.3 이상이어야한다.
Prepare the training data
- 튜토리얼에서는 학습 데이터로 꽃 데이터 세트를 이용한다. 데이터는 5개의 꽃 클래스를 포함한다.
- 사진을 훈련 데이터와 검증 데이터로 랜덤으로 섞어서 분류한다. 이후 사진 폴더명에 따라 레이블 파일을 생성한다.
우선 데이터를 다운받는다.
_URL = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
zip_file = tf.keras.utils.get_file(origin=_URL,
fname="flower_photos.tgz",
extract=True)
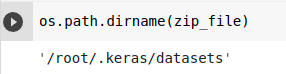
flowers_dir = os.path.join(os.path.dirname(zip_file), 'flower_photos')꽃 데이터는 다음 경로에 저장된다. 본인이 원한다면 위 코드를 변형하여 저장되는 위치를 바꾸면 되겠다.
다음으로 ImageDataGenerator를 이용하여 이미지 데이터의 부동 소수점 값을 재조정하고(픽셀을 255로 나누어 텐서 값이 0~1을 갖도록 조정), flow_from_directory()를 호출하여 2개의 generator(training dataset 용과 validation dataset 용)을 생성한다.
IMAGE_SIZE = 224
BATCH_SIZE = 64
datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255,
validation_split=0.2)
train_generator = datagen.flow_from_directory(
flowers_dir,
target_size=(IMAGE_SIZE, IMAGE_SIZE),
batch_size=BATCH_SIZE,
subset='training')
val_generator = datagen.flow_from_directory(
flowers_dir,
target_size=(IMAGE_SIZE, IMAGE_SIZE),
batch_size=BATCH_SIZE,
subset='validation')- ImageDataGenerator(rescale, validation_split): 255로 나누어 스케일을 정규화하고, 데이터의 20%는 검증 set로 분리한다.
- flow_from_dirctory(image path, target_size, batch_size, subset): 이미지를 불러올 때 폴더명에 맞춰 레이블을 생성하는 함수이다. subset은 ImageDataGenerator에서 validation_split이 세팅되면 따라오는 매개변수로 훈련과 검증을 구분하여 적으면 되겠다.
- 각 epoch마다 generator들은 디스크에서 이미지를 읽고 텐서 크기(224 x 224)로 처리하여 이미지 배치를 제공한다. 출력은 (image, label)의 튜플이다. 다음 코드로 이미지 배치의 shape을 알 수 있다.
image_batch, label_batch = next(val_generator)
image_batch.shape, label_batch.shape
이제 클래스 레이블을 텍스트 파일로 저장한다.
print (train_generator.class_indices)
labels = '\n'.join(sorted(train_generator.class_indices.keys()))
with open('flower_labels.txt', 'w') as f:
f.write(labels){'daisy': 0, 'dandelion': 1, 'roses': 2, 'sunflowers': 3, 'tulips': 4}- class_indices 속성을 이용하여 클래스의 이름과 인덱스의 매핑이 어떻게 이뤄졌는지를 알 수 있다.
레이블 txt 파일은 다음과 같이 저장된다.
!cat flower_labels.txtdaisy
dandelion
roses
sunflowers
tulips
Build the model
이제 우리는 마지막 fully-connected layer에서만 전이학습이 가능한 모델을 만들 것이다.
- 우선 keras의 MobileNet V2를 기본 모델로 시작한다. 이 모델은 ImageNet 데이터셋을 기반으로 1000개의 클래스에 대해서 인식이 가능하도록 훈련이 되었다. 이 모델을 사용함으로써 특징 추출과 꽃 데이터 셋을 다시 분류 레이어에 학습시키는 것이 용이할 것이다.
Create the base model
- MobileNetV2 모델을 시작할 때, 우리는 기본 모델인 base_model을 만들고 classification을 학습할 것이므로 classification layers 없이 네트워크를 불러오기 위해서는 include_top=False로 설정해야한다.
- 그리고 trainable을 False로 지정하여 base_model의 가중치가 학습되지 않도록 설정한다.
- 훈련시킬 classification layer의 앞에 위치한 어느정도 학습된 가중치와 편향을 가진 lower layer가 있는 모델이기 때문에 특징 추출에 효과적인 모델이 된다.
IMG_SHAPE = (IMAGE_SIZE, IMAGE_SIZE, 3)
# Create the base model from the pre-trained MobileNet V2
base_model = tf.keras.applications.MobileNetV2(input_shape=IMG_SHAPE,
include_top=False,
weights='imagenet')
base_model.trainable = False
Add a classification head
- Sequential model을 새로 만든다. base_model을 기본으로 앞에 두고, 그 뒤에 classification layer를 추가한다.
- 이미지 분류에 특화된 relu 함수를 사용하고 드랍아웃을 0.2로 지정하여 과대적합이 일어나지 않도록 한다.
- Global Average Pooling은 인풋을 전역 평균으로 풀링한다. 기존의 pooling 방식보다 훨씬 급격하게 feature의 수를 줄인다. 같은 채널의 특성값들을 모두 평균을 내어 채널의 개수만큼의 원소를 갖는 1차원 벡터로 만든다.
- 이 방식을 이용하면 기존의 CNN의 Flatten 층에 의해 파라미터가 급증하여 연산이 오래 걸리는 문제를 해결할 수 있다. 임베디드 환경에서 적합한 Pooling 방식이다.
- 그리고 마지막에 하나의 Dense 층을 둔다. Dense의 유닛 개수는 5개로 이 예제에서 사용하는 꽃 레이블 5개에 맞췄다. activation function은 softmax를 이용한다.
model = tf.keras.Sequential([
base_model,
tf.keras.layers.Conv2D(filters=32, kernel_size=3, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(units=5, activation='softmax')
])
Configure the model
이제 모델의 골격을 생성했으니 compile() 함수를 이용하여 모델의 세부적인 특징을 결정한다.
- optimizer는 adam을 이용한다.
- 다중 분류 모델이므로 loss function으로 categorical_crossentropy를 이용한다. (one-hot encoding)
- metrics 매개변수에 accuracy만 측정항목을 설정했다. 본인이 원하는 항목이 더 있으면 추가해서 넣으면 된다.
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
summary() 함수를 이용하면 모델의 최종 형태를 볼 수 있다.
model.summary()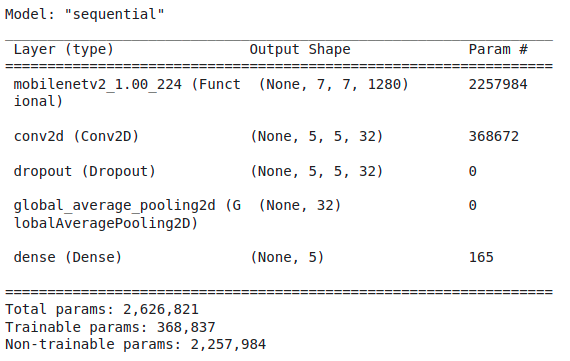
우리는 base_model의 가중치는 학습하지 않는다. 훈련되는 classification layer의 가중치의 개수는 다음 함수로 알 수 있다.
print('Number of trainable weights = {}'.format(len(model.trainable_weights)))Number of trainable weights = 4총 4개의 가중치가 학습된다.
Train the model
드디어 모델을 모두 구성했으므로 학습을 진행한다. 이전에 이미지 데이터를 training set과 validation set으로 나눴다.
그것을 가져와서 학습을 진행한다.
- 모델 학습 횟수는 10번, 가중치와 편항의 업데이트는 train_generator의 크기만큼 이뤄진다.
history = model.fit(train_generator,
steps_per_epoch=len(train_generator),
epochs=10,
validation_data=val_generator,
validation_steps=len(val_generator))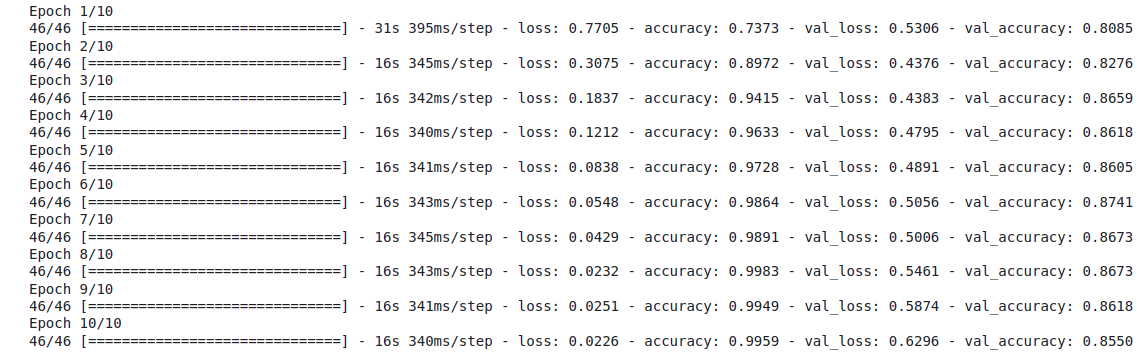
훈련 세트에는 잘 맞고, 검증 세트에는 성능이 떨어지는 전형적인 과대적합 모델이다..
일단 튜토리얼에서는 이런 결과가 나왔다. 결과가 마음에 안들면 모델을 새로 구성하길 바란다.
Review the learning curves
모델의 학습 과정을 그래프로 그린다.
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.figure(figsize=(8, 8))
plt.subplot(2, 1, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.ylabel('Accuracy')
plt.ylim([min(plt.ylim()),1])
plt.title('Training and Validation Accuracy')
plt.subplot(2, 1, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.ylabel('Cross Entropy')
plt.ylim([0,1.0])
plt.title('Training and Validation Loss')
plt.xlabel('epoch')
plt.show()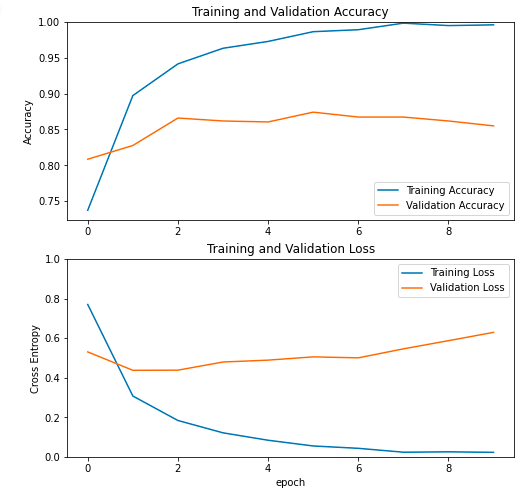
역시나 훈련 세트는 계속해서 Loss가 0에 수렴해갔지만 검증 세트는 오히려 손실이 증가하는 추세를 보인다.
일단 튜토리얼대로 고치지 않고 계속 진행하겠다.
Fine tune the base model
우리는 classification layer만 학습했고 base_model의 가중치는 학습하지 않았다.
훈련의 정확도를 높이기 위해서 동결시켰던 base_model의 일부 layer를 학습시킬 것이다. 해당 layer들의 가중치(1000개의 클래스에 적합하게 학습된 모델의 가중치)를 이번 튜토리얼에서 진행하는 꽃 데이터셋에 좀더 적합하도록 fine tune을 진행한다.
Un-freeze more layers
base_model의 layer 수는 다음과 같다.
print("Number of layers in the base model: ", len(base_model.layers))Number of layers in the base model: 154이 중 100개의 layer는 동결시키고 나머지 54개를 학습할 것이다.
- base_model의 훈련을 허용한다.
- fine_tune은 100번째 layer에서 시작한다.
- 0~99번째 layer는 학습을 하지 않도록 for 문을 이용하여 설정한다.
base_model.trainable = True
fine_tune_at = 100
# Freeze all the layers before the `fine_tune_at` layer
for layer in base_model.layers[:fine_tune_at]:
layer.trainable = False
Reconfigure the model
모델의 컴파일을 다시 진행한다. adam optimizer의 학습률은 기본 0.001인데 여기서는 0.00001로 하향하였다.
나머지는 이전과 동일하다.
model.compile(optimizer=tf.keras.optimizers.Adam(1e-5),
loss='categorical_crossentropy',
metrics=['accuracy'])
summary() 함수를 이용하여 모델의 구성을 다시 확인한다.
model.summary()
당연히 층의 구성은 변경하지 않았으니 골격은 똑같다. 그러나 하단을 보면 훈련 파라미터의 개수가 대략 2백만개 증가한 것을 알 수 있다. 따라서 시간을 오래 걸리지만 훨씬 정확한 모델이 만들어질 것이다.
print('Number of trainable weights = {}'.format(len(model.trainable_weights)))Number of trainable weights = 58조정하는 weight의 수도 58개로 증가하였다.
Continue training
이제 모델을 모두 구성했으니 훈련을 다시 진행한다. 이미 이전에 classification layer를 10번 가량 충분히 학습했기 때문에 여기서는 많은 epoch가 필요없다고 판단한다. 따라서 5번만 학습을 진행한다.
history_fine = model.fit(train_generator,
steps_per_epoch=len(train_generator),
epochs=5,
validation_data=val_generator,
validation_steps=len(val_generator))
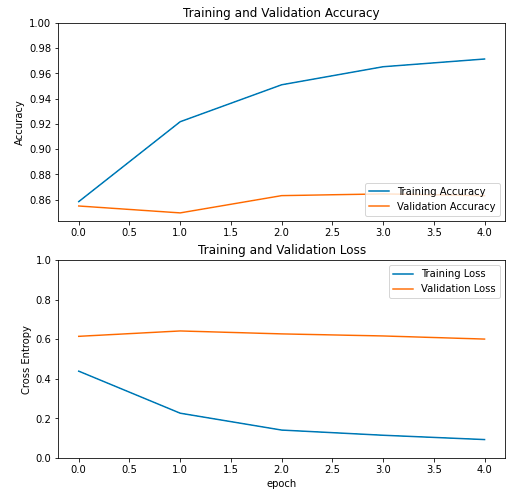
아.. 이전보다 아주 조금 val_loss가 감소하고, val_accuracy가 증가하긴 했다.. 드라마틱한 변화는 없었다.
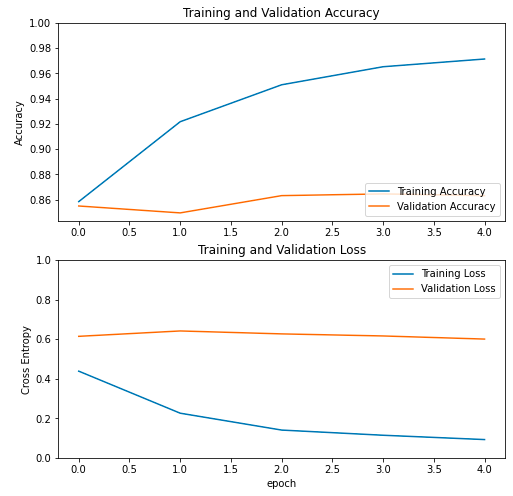
그래프를 보면 이전보다 조금 나아진 것 같기도 하다.
val의 성능이 진짜 모델의 성능이라고 할 수 있는데 이전에는 훈련이 무색하게 상승하던 validation set의 loss가 어느정도 유지(?)되는 경향을 보인다.

이미 구글 본인들도 알고 있다. 조금 더 낫긴한데 좋은 건 아니라고..
명백한 과대적합 모델이다. 새로운 꽃 데이터가 별로 좋지 않은 데이터여서 과대적합이 발생하는 게 당연하다고 한다.
일단 어쩔 수 없다고 하니 계속 진행하겠다.
Convert to TFLite
이제 모델을 경량화한다. 고작 다음의 몇 줄 안되는 코드만 입력하면 TFLite 모델로 변환이 가능하다.
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
with open('mobilenet_v2_1.0_224.tflite', 'wb') as f:
f.write(tflite_model)생성한 모델을 TFLiteConverter를 이용하여 변환하고 저장하였다.
그런데 아직 이 .tflite 파일은 부동 소수점 파라미터를 가진다. 따라서 완전히 int8 format으로 양자화하는 것이 필요하다.
이를 위해 post-training quatization을 수행한다. 따라서 위의 코드가 아니라 사실은 아래처럼 조금은 더 긴 코드를 써야 한다.
# A generator that provides a representative dataset
def representative_data_gen():
dataset_list = tf.data.Dataset.list_files(flowers_dir + '/*/*')
for i in range(100):
image = next(iter(dataset_list))
image = tf.io.read_file(image)
image = tf.io.decode_jpeg(image, channels=3)
image = tf.image.resize(image, [IMAGE_SIZE, IMAGE_SIZE])
image = tf.cast(image / 255., tf.float32)
image = tf.expand_dims(image, 0)
yield [image]
converter = tf.lite.TFLiteConverter.from_keras_model(model)
# This enables quantization
converter.optimizations = [tf.lite.Optimize.DEFAULT]
# This sets the representative dataset for quantization
converter.representative_dataset = representative_data_gen
# This ensures that if any ops can't be quantized, the converter throws an error
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
# For full integer quantization, though supported types defaults to int8 only, we explicitly declare it for clarity.
converter.target_spec.supported_types = [tf.int8]
# These set the input and output tensors to uint8 (added in r2.3)
converter.inference_input_type = tf.uint8
converter.inference_output_type = tf.uint8
tflite_model = converter.convert()
with open('mobilenet_v2_1.0_224_quant.tflite', 'wb') as f:
f.write(tflite_model)주석때문인지 몰라도 코드가 갑자기 길어졌다.
훈련 데이터 중 대표 데이터 세트를 만드는 함수가 존재하고, 그것을 이용해서 양자화를 어떻게 할지 파악하고 실시한다.
최종적으로 int8 format으로 파라미터가 조정된 경량화 모델이 생성된다.
Compare the accuracy
우리한테는 이제 완전히 int8 format으로 변환된 TFLite model이 있다.
변환이 제대로 이뤄졌는지 확인하기 위해서 변환전 모델과 변환후 모델의 정확도를 비교하겠다.
batch_images, batch_labels = next(val_generator)
logits = model(batch_images)
prediction = np.argmax(logits, axis=1)
truth = np.argmax(batch_labels, axis=1)
keras_accuracy = tf.keras.metrics.Accuracy()
keras_accuracy(prediction, truth)
print("Raw model accuracy: {:.3%}".format(keras_accuracy.result()))Raw model accuracy: 81.250%변환전 모델의 정확도는 81.250%이다.
TFLite 모델의 정확도를 측정하기 위한 편리한 API가 없어서 우리가 해당 Label라고 결론냈으면 하는 예측을 바탕으로 추론 및 비교를 진행한다고 한다.
def set_input_tensor(interpreter, input):
input_details = interpreter.get_input_details()[0]
tensor_index = input_details['index']
input_tensor = interpreter.tensor(tensor_index)()[0]
# Inputs for the TFLite model must be uint8, so we quantize our input data.
# NOTE: This step is necessary only because we're receiving input data from
# ImageDataGenerator, which rescaled all image data to float [0,1]. When using
# bitmap inputs, they're already uint8 [0,255] so this can be replaced with:
# input_tensor[:, :] = input
scale, zero_point = input_details['quantization']
input_tensor[:, :] = np.uint8(input / scale + zero_point)
def classify_image(interpreter, input):
set_input_tensor(interpreter, input)
interpreter.invoke()
output_details = interpreter.get_output_details()[0]
output = interpreter.get_tensor(output_details['index'])
# Outputs from the TFLite model are uint8, so we dequantize the results:
scale, zero_point = output_details['quantization']
output = scale * (output - zero_point)
top_1 = np.argmax(output)
return top_1
interpreter = tf.lite.Interpreter('mobilenet_v2_1.0_224_quant.tflite')
interpreter.allocate_tensors()
# Collect all inference predictions in a list
batch_prediction = []
batch_truth = np.argmax(batch_labels, axis=1)
for i in range(len(batch_images)):
prediction = classify_image(interpreter, batch_images[i])
batch_prediction.append(prediction)
# Compare all predictions to the ground truth
tflite_accuracy = tf.keras.metrics.Accuracy()
tflite_accuracy(batch_prediction, batch_truth)
print("Quant TF Lite accuracy: {:.3%}".format(tflite_accuracy.result()))Quant TF Lite accuracy: 81.250%변환후 모델의 정확도 역시 81.250%가 나왔다. 정확도가 떨어지지 않았다고 생각할 수 있지만 실제 기동에서는 이러한 결과가 적합하지 않을 수 있다고 한다.
Compile for the Edge TPU
이제 드디어 Edge TPU에 사용할 수 있도록 컴파일을 진행한다.
우선 Edge TPU Compiler를 다운로드한다.
! curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
! echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /etc/apt/sources.list.d/coral-edgetpu.list
! sudo apt-get update
! sudo apt-get install edgetpu-compiler
컴파일러를 다운받았다면 이제 모델을 컴파일한다.
! edgetpu_compiler mobilenet_v2_1.0_224_quant.tflite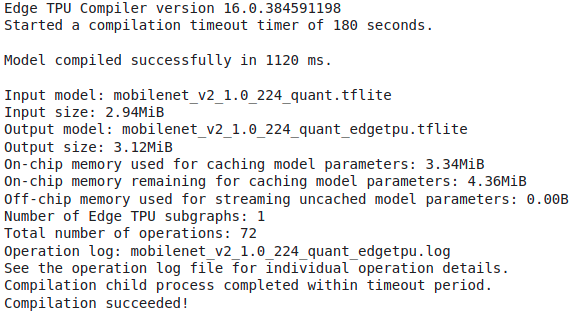
동일한 모델이지만 뒤에 _edgetpu가 모델명에 추가된 모델을 얻었다.
Download the model
구글 코랩에서 완성시킨 모델을 다운로드할 수 있다.
다운로드하는 파일은 모델.tflite와 레이블.txt이다.
from google.colab import files
files.download('mobilenet_v2_1.0_224_quant_edgetpu.tflite')
files.download('flower_labels.txt')
정상적으로 다운로드되었다.
Run the model on the Edge TPU
이제 이 모델은 Edge TPU를 가진 제품에 돌릴 수 있다.
다음과 같은 형태로 py 파일과 모델, 레이블, input을 지정하여 추론을 진행할 수 있다.
python3 classify_image.py \
--model mobilenet_v2_1.0_224_quant_edgetpu.tflite \
--labels flower_labels.txt \
--input flower.jpg
실제로 구동하기
나는 Google DevBoard는 없지만 Google Coral Accelerator를 가지고 있다.
그래서 위의 모델을 구동할 수 있다.
daisy
dandelion
roses
sunflowers
tulips레이블에는 총 5개의 레이블이 들어있다.
나는 이중에서 sunflower의 이미지를 인터넷에서 다운받아서 진행했다.

위의 해바라기 사진을 classify해보았다.
python3 examples/classify_image.py \
--model test_data/mobilenet_v2_1.0_224_quant_edgetpu.tflite \
--labels test_data/flower_labels.txt \
--input test_data/sunflower_example.jpeg파일의 경로를 정확히 지정하는 것에 유의하자.
----INFERENCE TIME----
Note: The first inference on Edge TPU is slow because it includes loading the model into Edge TPU memory.
11.6ms
4.2ms
4.1ms
4.2ms
4.2ms
-------RESULTS--------
sunflowers: 0.99609상당히 높은 정확도로 이 사진이 해바라기임을 알아냈다.
출처